Tuning LLVM's SLP Vectorizer Cost Model

Similar to my last post, this writeup covers how I solved a performance regression on LLVM by analyzing a benchmark from a RISCV target.
The Regression
Looking at Igalia’s LNT instance for the BPI-F3, I noticed this particular benchmark with a delta of 89%. Specifically, there was an increase in ~26% issued instructions and a ~48% increase in cycles.

I have attached two more pictures right below, with the first one being the assembly of a basic block from the older build and the corresponding assembly from the newer build.
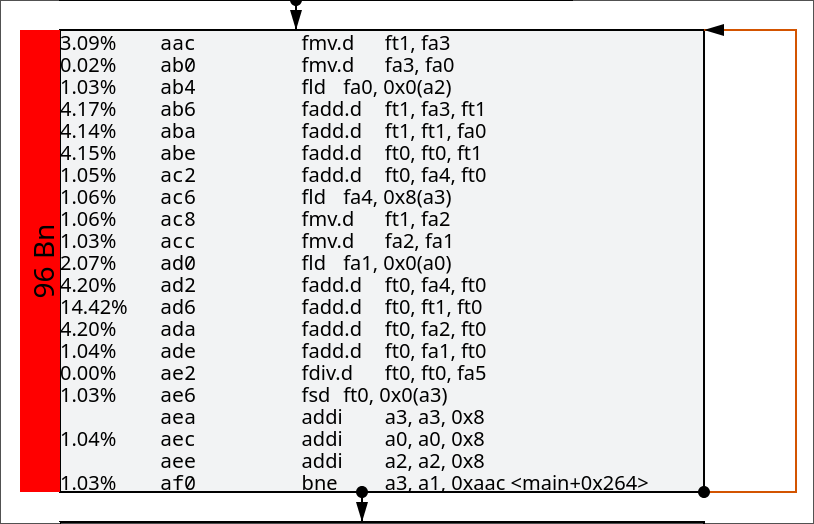
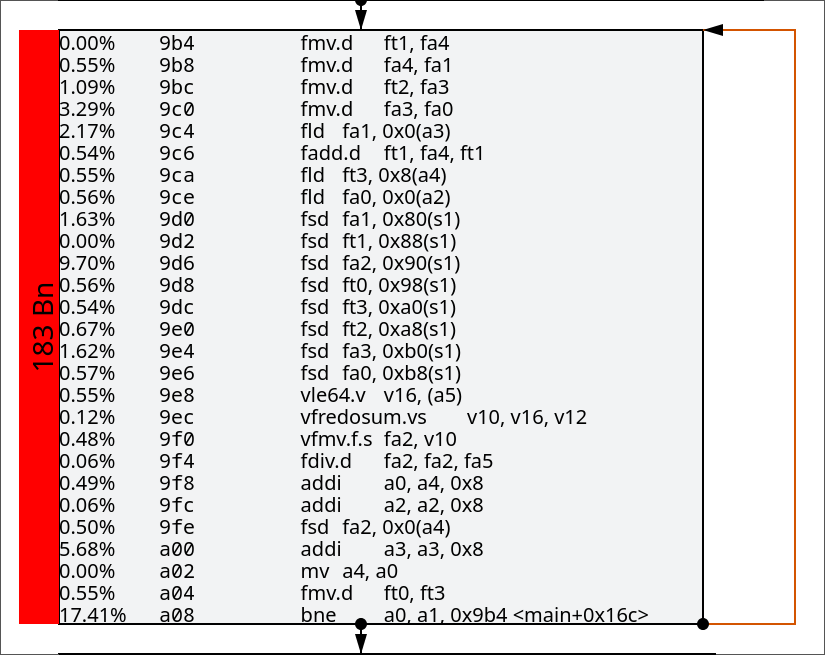
Info
Bn here refers to Billions of cycles. This basic block is basically taking twice as many cycles to execute.
We can see that that newer build of LLVM is performing a sequence of fsd instructions, also known as Float Store Double. It’s essentially storing the floating point values from those registers onto the stack. Specifically, it’s storing the value at the address s1 + 0x80.
From a preceding basic block that I have not included here, I know that value of the register a5 to be equal to s1 + 0x80 from this instruction.
addi a5, s1, 0x80The Vector Load Instruction vle64.v is loading the values from memory at the address at a5 (s1 + 0x80) into the vector register v16.
v16 = M[a5]Finally, it executes the vfredosum.vs instruction (Ordered floating-point sum), which performas the following for a vector register of size VL.
The new codegen is basically trying to replace the ordered fadd instructions in the first basic block with this vector sum reduction instruction. I hope this diagram may illustrate this better, with what was previously happening versus what is currently occurring. From the images above, it can be observed that the new code is significantly more expensive in terms of cycles.
graph LR
%% Left-to-Right top level allows parallel tracks to scale height independently
V_IN["Original Source Data<br/><i>(Residing in Scalar Registers)</i>"]
%% Link to Scalar Track
V_IN -->|Old Execution| S1
%% Link to Vector Track
V_IN -->|New Execution| FSD1
%% Left Side Track: Original Scalar Chain
subgraph ScalarChain ["Original Intent: Ordered fadd Chain"]
direction TB
S1["fadd (START_VAL + SCALAR_VAL_0)"] --> S2["fadd (Result + SCALAR_VAL_1)"]
S2 --> S3["fadd (Result + SCALAR_VAL_2)"]
S3 --> S4["fadd (Result + SCALAR_VAL_3)<br/><code>FINAL_SCALAR_SUM</code>"]
end
%% Right Side Track Part 1: Memory Gather (Now cleanly scales to its actual contents)
subgraph Gather ["Memory Gather (Stack Spilling Penalty)"]
direction TB
FSD1["Store SCALAR_VAL_0 to s1 + 0x80"]
FSD2["Store SCALAR_VAL_1 to s1 + 0x88"]
FSD3["Store SCALAR_VAL_2 to s1 + 0x90"]
FSD4["Store SCALAR_VAL_3 to s1 + 0x98"]
end
subgraph VectorOps ["Vector Load & Reduction"]
direction TB
VLE["Vector Load<br/><i>(Loads from memory into vector register v16)</i>"] --> VFRED["Vector Ordered Sum Reduction<br/><i>(vfredosum)</i>"]
end
%% Connect the two vector halves sequentially
FSD4 -->VLE
%% --- STYLING BLOCK ---
style ScalarChain fill:none,stroke:#888888,stroke-dasharray: 5 5
%% Gather Penalty (Soft Red Glow)
style Gather fill:#b71c1c18,stroke:#ef4444,stroke-width:2px,rx:8,ry:8
%% Vector Operations (Soft Blue Glow)
style VectorOps fill:#0d47a118,stroke:#3b82f6,stroke-width:2px,rx:8,ry:8
Info
If you visit the link yourself, you may notice that there is also another basic block further down that also has a significant increase in cycles compared to its older counterpart. I chose not to include that as both of them are identical, so fixing one fixes the other.
The Where?
To narrow down where these new fsd and vfredosum.vs instructions are introduced, I ran the command below to get emit the LLVM IR. The output of this commend will give us the intermediate representation produced by the middle-end. If we can observe IR code that would result in those instructions, we can rule out the backend.
$lbd/bin/clang -O3 \
--target=riscv64-unknown-linux-gnu \
-march=rva22u64_v \
--gcc-toolchain=/usr \
--sysroot=/usr/riscv64-linux-gnu \
-I. \
-DFP_ABSTOLERANCE=1e-5 \
-S -emit-llvm seidel-2d.c \
-o seidel-2d.llfor.body8.i: ; preds = %for.body8.i, %for.cond5.preheader.i
%18 = phi double [ %.pre117.i, %for.cond5.preheader.i ], [ %26, %for.body8.i ]
%19 = phi double [ %.pre116.i, %for.cond5.preheader.i ], [ %18, %for.body8.i ]
%20 = phi double [ %.pre115.i, %for.cond5.preheader.i ], [ %25, %for.body8.i ]
%21 = phi double [ %.pre114.i, %for.cond5.preheader.i ], [ %div.i40, %for.body8.i ]
%22 = phi double [ %.pre113.i, %for.cond5.preheader.i ], [ %24, %for.body8.i ]
%23 = phi double [ %.pre.i, %for.cond5.preheader.i ], [ %22, %for.body8.i ]
%indvars.iv.i38 = phi i64 [ 1, %for.cond5.preheader.i ], [ %indvars.iv.next.i39, %for.body8.i ]
%add.i = fadd double %22, %23
%indvars.iv.next.i39 = add nuw nsw i64 %indvars.iv.i38, 1
%arrayidx23.i = getelementptr inbounds nuw [8 x i8], ptr %arrayidx.i37, i64 %indvars.iv.next.i39
%24 = load double, ptr %arrayidx23.i, align 8, !tbaa !14
%arrayidx34.i = getelementptr inbounds nuw [8 x i8], ptr %17, i64 %indvars.iv.i38
%arrayidx40.i = getelementptr inbounds nuw [8 x i8], ptr %17, i64 %indvars.iv.next.i39
%25 = load double, ptr %arrayidx40.i, align 8, !tbaa !14
%arrayidx60.i = getelementptr inbounds nuw [8 x i8], ptr %arrayidx44.i, i64 %indvars.iv.next.i39
%26 = load double, ptr %arrayidx60.i, align 8, !tbaa !14
%27 = insertelement <8 x double> poison, double %24, i32 0
%28 = insertelement <8 x double> %27, double %add.i, i32 1
%29 = insertelement <8 x double> %28, double %21, i32 2
%30 = insertelement <8 x double> %29, double %20, i32 3
%31 = insertelement <8 x double> %30, double %25, i32 4
%32 = insertelement <8 x double> %31, double %19, i32 5
%33 = insertelement <8 x double> %32, double %18, i32 6
%34 = insertelement <8 x double> %33, double %26, i32 7
%35 = call double @llvm.vector.reduce.fadd.v8f64(double -0.000000e+00, <8 x double> %34)
%div.i40 = fdiv double %35, 9.000000e+00
store double %div.i40, ptr %arrayidx34.i, align 8, !tbaa !14
%exitcond.not.i41 = icmp eq i64 %indvars.iv.next.i39, 1999
br i1 %exitcond.not.i41, label %for.inc66.i, label %for.body8.i, !llvm.loop !25We can observe here a chain of insertelement instructions building an <8 x double> vector. The instruction follows this format:
%result = insertelement <vector_type> <source_vector>, <scalar_value>, <index>Using the snippet above, we can see that %27 is the initial vector. Because there is no prior value, the source is marked as poison, the scalar value it’s inserting is the value %24, and the index is 0. From there, each subsequent instruction feeds the result of the previous line its source vector operand.
Once the vector is completely packed at %34, it serves as an operand to the vector.reduce.fadd intrinsic (maps to vfredosum). The LLVM LangRef explains how this intrinsic sums up the elements in the second operand (34%), and adds the first operand (0.0), and stores the result (%35). The pseudocode provided by the LangRef probably explains this better.
float sequential_fadd(start_value, input_vector)
result = start_value // This is -0.00000
for i = 0 to length(input_vector) // Traverses every element in %34
result = result + input_vector[i]
return resultIntrinsic
LLVM intrinsics are built-in functions that map directly to low-level architecture instructions, but can be hard to express in normal LLVM IR semantics. They give the compiler a better understanding of a hardware operation, allowing it to generate more efficient assembly.
Since the behaviour is already introduced by the middle-end, we can rule out the RISCV backend. I can confidently say that it was some middle-end pass causing this behaviour.
This gives us a better idea of what to isolate. I ran git log on the dates of when the builds were ran, and grepped for keywords. After hitting a couple of dead-ends, I found a promising lead when I filtered specifically for reduction.
git log --since="2026-05-19 00:00:00 +0000" --until="2026-05-20 00:13:39 +0000" --oneline | grep reduc
e28e7ec30357 Reland [VectorCombine] foldShuffleChainsToReduce - add support for partial vector reductions (#197659)
dfa05b675eee [VectorCombine] Fold reduce.add == 0 into reduce.[or,umax] == 0 (#180001)
230980947083 [SLP] Support ordered fadd reduction via reduction intrinsics
2d9407bb56b7 [X86] Add handling for sub-128bit minmax reductions (#198319)The third commit immediately stood out, as its description would perfectly explain the new codegen. After building LLVM locally before and with this commit, I was able to determine that the commit was the culprit.
The Why?
For some reason, the SLP Vectorizer thinks it more profitable to performed the fadd reduction here when we know from the benchmark that its not. The key things that author added in that commit were the following:
matchOrderedReduction- Responsible for finding possible instructions for ordered reduction.
tryToReduceOrdered- This is the function that actually checks if its profitable, and commits to the ordered reduction if it is.
SLP Vectorizer
I think the LLVM docs does a decent job at a high-level overview of what the SLPVectorizer does. LLVM has two vectorizers, and the SLP Vectorizer is one of them. The pass’ main goal is to combine independent instructions into vector instructions. This is a pretty important in terms of performance. By vectorizing what was previously scalar instructions, you can perform the same operations on multiple values at once. This is especially beneficial when operations within a loop can be vectorized, as these tend to be the hotspots within a program.
In this case though, the SLP Vectorizer was vectorizing a sequence of ordered instructions. I think the commit message itself will elucidate the goal of this commit better.
Previously, the SLP vectorizer could only vectorize ordered reductions by keeping the original scalar chain and emitting extractelement instructions. The new path replaces the scalar chain with a vector ordered reduction intrinsic (where profitable), which allows the backend to lower it more efficiently.
The following test case from the PR further illustrates the goal of the commit.
- ; CHECK-NEXT: [[TMP28:%.*]] = extractelement <4 x float> [[TMP17]], i32 0
- ; CHECK-NEXT: [[TMP32:%.*]] = extractelement <4 x float> [[TMP17]], i32 1
- ; CHECK-NEXT: [[ADD30:%.*]] = fadd float [[TMP28]], [[TMP32]]
- ; CHECK-NEXT: [[TMP20:%.*]] = extractelement <4 x float> [[TMP17]], i32 2
- ; CHECK-NEXT: [[ADD31:%.*]] = fadd float [[ADD30]], [[TMP20]]
- ; CHECK-NEXT: [[TMP30:%.*]] = extractelement <4 x float> [[TMP17]], i32 3
- ; CHECK-NEXT: [[ADD33:%.*]] = fadd float [[ADD31]], [[TMP30]]
+ ; CHECK-NEXT: [[ADD33:%.*]] = call float @llvm.vector.reduce.fadd.v4f32(float -0.000000e+00, <4 x float> [[TMP17]])
Before this commit, LLVM had to extract elements out of a vector to perform a chain of scalar fadd. This commit notices that it’s cheaper to keep them in the vector, and use the reduction intrinsic (which maps to vfredosum on RISCV).
graph TD
%% Top Level Input
V_IN["Source Vector Input<br/><code>VECTOR_INPUT</code>"]
%% Split Path
V_IN -->|Old Code Generation| OldBehavior
V_IN -->|Optimized SLP Rewrite| NewBehavior
%% Left Side Path: Old Behavior (The Costly Extraction Chain)
subgraph OldBehavior ["Before: Extraction Penalty"]
direction TB
%% Extraction Row
subgraph Extractions ["Explicit Extractions"]
E0["extractelement (EL0)"]
E1["extractelement (EL1)"]
E2["extractelement (EL2)"]
E3["extractelement (EL3)"]
end
%% Chain
A0["fadd (EL0 + EL1)"]
A1["fadd (Result + EL2)"]
A2["fadd (Result + EL3)<br/><code>FINAL_SCALAR_SUM</code>"]
%% Wire it up
E0 & E1 --> A0
A0 & E2 --> A1
A1 & E3 --> A2
end
%% Right Side Path: New Behavior (The Native Intrinsic)
subgraph NewBehavior ["Direct Reduction"]
direction TB
INTRINSIC["<b>@llvm.vector.reduce.fadd</b><br/><i>Executes natively inside the vector unit</i><br/><code>FINAL_SCALAR_SUM</code>"]
end
%% --- STYLING BLOCK ---
style OldBehavior fill:none,stroke:#888888,stroke-dasharray: 5 5
style NewBehavior fill:none,stroke:#888888,stroke-dasharray: 5 5
style Extractions fill:none,stroke:none
%% Highlight the bad overhead path in red
style E0 fill:#b71c1c18,stroke:#ef4444,stroke-width:1px
style E1 fill:#b71c1c18,stroke:#ef4444,stroke-width:1px
style E2 fill:#b71c1c18,stroke:#ef4444,stroke-width:1px
style E3 fill:#b71c1c18,stroke:#ef4444,stroke-width:1px
%% Highlight the clean vector intrinsic win in green
style INTRINSIC fill:#1b5e2018,stroke:#4caf50,stroke-width:2px,rx:8,ry:8
TreeEntry
The TreeEntry is a datastructure used to hold relevant data to determine which scalar operations can be combined into vector operations. The log below was printed using TE.dump() on the benchmark.
==== [SLP Cost Loop] Examining TreeEntry (Idx: 0) ====
0.
Scalars:
%45 = load double, ptr %arrayidx23.i75, align 8, !tbaa !16
%add.i73 = fadd double %43, %44
%42 = phi double [ %.pre114.i65, %for.cond5.preheader.i58 ], [ %div.i86, %for.body8.i71 ]
%41 = phi double [ %.pre115.i67, %for.cond5.preheader.i58 ], [ %46, %for.body8.i71 ]
%46 = load double, ptr %arrayidx40.i80, align 8, !tbaa !16
%40 = phi double [ %.pre116.i68, %for.cond5.preheader.i58 ], [ %39, %for.body8.i71 ]
%39 = phi double [ %.pre117.i70, %for.cond5.preheader.i58 ], [ %47, %for.body8.i71 ]
%47 = load double, ptr %arrayidx60.i84, align 8, !tbaa !16
State: NeedToGather
MainOp: NULL
AltOp: NULL
VectorizedValue: NULL
ReuseShuffleIndices: Empty
ReorderIndices:
UserTreeIndex: <invalid>I’m not a 100% sure why there are phi instructions within Scalars, but I’m fairly sure it’s because the function matchOrderedReduction, which is responsible for finding ordered operations, walks back to the root of the instructions. The comments on this function may explain this better.
/// Analyze whether \p Root forms a linearized ordered reduction chain.
/// If \p MatchLHS is true, analyzes LHS-associated (left-linearized) chains
/// where the chain recurses on the LHS and the RHS at each level is a leaf:
/// ((((v0 op v1) op v2) op v3) op v4)
/// If \p MatchLHS is false, analyzes RHS-associated (right-linearized) chains
/// where the chain recurses on the RHS and the LHS at each level is a leaf:
/// (v0 op (v1 op (v2 op (v3 op v4))))
/// Leaf values are stored in ReducedVals.back() in accumulation order
/// (innermost pair first, outermost last), e.g. [v0,v1,v2,v3,v4] for
/// LHS-associated and [v4,v3,v2,v1,v0] for RHS-associated chains.
/// \returns true if the chain is a valid ordered reduction.
The key thing to notice is that the UserTreeIndex is invalid. tryToReduceOrdered builds an isolated tree by calling V.buildTree(VL, IgnoreList) specifically for the ordered reduction candidates. Since this is the root, there is no parent, so EI (EdgeInfo) would be null.
Tracing the logs to the code
I first raised an issue and pinged the author of the commit with a kind of hacky solution. He suggested an inaccurate TTI (Target Transform Info) for this particular target.
Issue: https://github.com/llvm/llvm-project/issues/199267
Target Transform Info (TTI)
LLVM middle-end tries to be target-agnostic. But it’s easy to imagine scenarios where we would need info on the target during the middle-end. For example, building the vector in this benchmark might be cheaper on other targets. Target Transform Info provides hooks that can be overridden by backends to provide info to the middle-end.
With this in mind, I kept investigating the code alongside the logs. I noticed this piece of code from the diff.
+ LLVM_DEBUG(dbgs() << "SLP: Vectorizing ordered reduction at cost:" << Cost
+ << ". (HorRdx)\n");
When the SLPVectorizer commits to performing an ordered reduction, it prints that debug statement alongside the cost. Searching through the log for this debug message, I found two instances of “Vectorizing ordered…”, which corresponds to the two basic blocks in this benchmark.
SLP: Adding cost 15 for bundle Idx: 0, n=8 [ %24 = load double, ptr %arrayidx23.i, align 8, !tbaa !16, ..].
SLP: Current total cost = 15
SLP: Adding cost -4 for reduction of n=8 [ %24 = load double, ptr %arrayidx23.i, align 8, !tbaa !16, ..] (It is a splitting reduction)
Scale 1996002000 For entry 0
SLP: Spill Cost = 0.
SLP: Extract Cost = 0.
SLP: Reduction Cost = -7984008000.
SLP: Total Cost = -7984007985.
SLP: Found cost = -7984007985 for ordered reduction
SLP: Vectorizing ordered reduction at cost:-7984007985. (HorRdx)From these logs, we can observe a couple of things:
- The value of
Scale, which is the number of iterations in a loop, is 1996002000. - The Reduction Cost was -7984008000, which I deduce is from the -4 being multiplied by the
Scalevalue - The TreeCost which encompasses the cost of the bundle in this case, which corresponds to the instructions building the vector to reduce it, is 15
- The total cost was -7894007895, the TreeCost subtracted by the ReductionCost
I hope the problem is clearer now. In this benchmark, the TreeCost - the cost to build the vector - is not scaled alongside the ReductionCost. This results in really big negative value, leading the SLPVectorizer to think this ordered reduction is profitable.
If you’re wondering where exactly the Scale came to be, this snippet from the source code can explain this.
// seidel-2d.h
/* Default to LARGE_DATASET. */
# if !defined(MINI_DATASET) && ...
# define LARGE_DATASET
# endif
# ifdef LARGE_DATASET
# define TSTEPS 500
# define N 2000
# endif
// seidel-2d.c
for (t = 0; t <= _PB_TSTEPS - 1; t++)
for (i = 1; i <= _PB_N - 2; i++)
for (j = 1; j <= _PB_N - 2; j++)If we look at the function getTreeCost, we can see how ReductionCost is scaled.
InstructionCost BoUpSLP::getTreeCost(InstructionCost TreeCost,
ArrayRef<Value *> VectorizedVals,
InstructionCost ReductionCost,
Instruction *RdxRoot) {
...
InstructionCost Cost = TreeCost;
SmallDenseMap<std::tuple<const TreeEntry *, Value *, Instruction *>, uint64_t>
EntryToScale;
auto ScaleCost = [&](InstructionCost C, const TreeEntry &TE,
Value *Scalar = nullptr, Instruction *U = nullptr) {
if (!C.isValid() || C == 0)
return C;
uint64_t &Scale =
EntryToScale.try_emplace(std::make_tuple(&TE, Scalar, U), 0)
.first->getSecond();
if (!Scale)
Scale = getScaleToLoopIterations(TE, Scalar, U);
LLVM_DEBUG(dbgs() << "Scale " << Scale << " For entry " << TE.Idx << "\n");
return C * Scale;
};
Instruction *ReductionRoot = RdxRoot;
if (UserIgnoreList) {
// Scale reduction cost to the factor of the loop nest trip count.
ReductionCost = ScaleCost(ReductionCost, *VectorizableTree.front().get(),
/*Scalar=*/nullptr, ReductionRoot);
}
// Add the cost for reduction.
Cost += ReductionCost;
...
}ReductionCost is being multiplied by the valued returned by getScaleToLoopIterations. The function getScaleToLoopIterations also has access to *RdxRoot, which gives getScaleToLoopIterations awareness of the parent block, and lets it figure out the number of iterations if the block is a loop.
To figure out why the TreeCost is not being scaled, lets again compare the logs to the code. By searching for “for bundle:”, I was able to find this snippet of the code in a function called calculateTreeCostAndTrimNonProfitable. As the name suggests, this is the function responsible for calculating the cost of TreeCost.
InstructionCost
BoUpSLP::calculateTreeCostAndTrimNonProfitable(ArrayRef<Value *> VectorizedVals,
Instruction *RdxRoot) {
...
InstructionCost C = getEntryCost(&TE, VectorizedVals, CheckedExtracts);
uint64_t Scale = 0;
bool CostIsFree = C == 0;
...
if (!CostIsFree && !Scale) {
Scale = IsGatherLike ? getGatherNodeEffectiveScale(TE)
: getScaleToLoopIterations(TE);
C *= Scale;
EntryToScale.try_emplace(&TE, Scale);
if (!TE.isGather() && TE.hasState()) {
PrevVecParent = TE.getMainOp()->getParent();
PrevScale = Scale;
}
}
Cost += C;
NodesCosts.try_emplace(&TE, C);
LLVM_DEBUG(dbgs() << "SLP: Adding cost " << C << " for bundle "
<< shortBundleName(TE.Scalars, TE.Idx) << ".\n"
<< "SLP: Current total cost = " << Cost << "\n");
...
}To get a better idea of what was happening, I added debug logs. From these logs, I determined that getGatherNodeEffectiveScale is called to calculate the Scale value here. This function then calls getScaleToLoopIterations.
uint64_t BoUpSLP::getScaleToLoopIterations(const TreeEntry &TE, Value *Scalar,
Instruction *U) {
BasicBlock *Parent = nullptr;
...
} else if (TE.isGather() || TE.State == TreeEntry::SplitVectorize) {
EdgeInfo EI = TE.UserTreeIndex;
while (EI.UserTE) {
...
}
if (!Parent)
return 1;
} else {
...
}In this case, EI.UserTE is null, so the (!Parent) would return true and the function would just return 1.
Landing a fix
I’ll be upfront in that the author, alexey-bataev, heavily guided me towards this fix. Take a look at the issue if you want to see my initial ideas on trying to solve this.
Here is a link to the final PR as well as the precommit test:
The solution was to pass the RdxRoot instruction to calculateTreeCostAndTrimNonProfitable, and subsequently to getGatherNodeEffectiveScale and getScaleToLoopIterations, so that they have the loop context needed to correctly scale TreeCost.
In simpler terms, Scale was previously being assigned the value of 1 because the pass did not have access to the parent block of the insertelement instructions. This patch addresses that.
graph TD
%% Main execution flow container
subgraph Pipeline ["The Fix: Passing RdxRoot"]
direction TB
%% Step 1
A["<b>tryToReduceOrdered</b><br/>Identifies reduction and holds reference to <code>RdxRootInst</code>"]
%% Step 2
B["<b>calculateTreeCostAndTrimNonProfitable</b><br/>Accepts new parameter: <code>Instruction *RdxRoot</code>"]
%% Step 3 (The Ternary Switch)
C{"Is the node<br/>Gather-Like?"}
%% Step 4a
D["<b>getGatherNodeEffectiveScale(TE, RdxRoot)</b><br/><i>(Applies to Root Node at TE.Idx == 0)</i>"]
%% Step 4b
E["<b>getScaleToLoopIterations(TE)</b>"]
%% Step 5
F["<b>getScaleToLoopIterations(TE, nullptr, U)</b><br/>Bypasses missing tree parent by anchoring to <code>U</code> (RdxRoot)"]
%% Define flow connections
A -->|Passes RdxRootInst| B
B --> C
C -->|Yes: Node is isolated| D
C -->|No: Standard node| E
D -->|Passes U to find loop context| F
end
%% --- STYLING BLOCK ---
%% Neutral structural wrapper for the pipeline
style Pipeline fill:none,stroke:#888888,stroke-dasharray: 5 5
%% Standard nodes styling
style A fill:none,stroke:#888888,stroke-width:1px
style B fill:none,stroke:#888888,stroke-width:1px
style C fill:none,stroke:#888888,stroke-width:1px
style E fill:none,stroke:#888888,stroke-width:1px
%% Highlights for where the fix actively changes behavior (Soft Green Glow)
style D fill:#1b5e2018,stroke:#4caf50,stroke-width:2px,rx:8,ry:8
style F fill:#1b5e2018,stroke:#4caf50,stroke-width:2px,rx:8,ry:8
diff --git a/llvm/lib/Transforms/Vectorize/SLPVectorizer.cpp b/llvm/lib/Transforms/Vectorize/SLPVectorizer.cpp
index 54a4d6b68b2e..d90eba7118b3 100644
--- a/llvm/lib/Transforms/Vectorize/SLPVectorizer.cpp
+++ b/llvm/lib/Transforms/Vectorize/SLPVectorizer.cpp
@@ -2176,7 +2176,8 @@ public:
/// Calculates the cost of the subtrees, trims non-profitable ones and returns
/// final cost.
InstructionCost
- calculateTreeCostAndTrimNonProfitable(ArrayRef<Value *> VectorizedVals = {});
+ calculateTreeCostAndTrimNonProfitable(ArrayRef<Value *> VectorizedVals = {},
+ Instruction *RdxRoot = nullptr);
/// \returns the vectorization cost of the subtree that starts at \p VL.
/// A negative number means that this is profitable.
@@ -3996,7 +3997,8 @@ private:
/// LICM hoisting that optimizeGatherSequence() performs after vectorization
/// for inserts with loop-invariant operands. Falls back to the whole-entry
/// scale when per-lane information is unavailable or the feature is off.
- uint64_t getGatherNodeEffectiveScale(const TreeEntry &TE);
+ uint64_t getGatherNodeEffectiveScale(const TreeEntry &TE,
+ Instruction *U = nullptr);
/// Get the loop nest for the given loop \p L.
ArrayRef<const Loop *> getLoopNest(const Loop *L);
@@ -16455,14 +16457,15 @@ uint64_t BoUpSLP::getLoopNestScale(const Loop *L) {
return std::max<uint64_t>(1, Scale);
}
-uint64_t BoUpSLP::getGatherNodeEffectiveScale(const TreeEntry &TE) {
+uint64_t BoUpSLP::getGatherNodeEffectiveScale(const TreeEntry &TE,
+ Instruction *U) {
// Only meaningful for gather/buildvector-like entries; the per-lane
// insertelements that make up such an entry are LICM-hoistable by
// optimizeGatherSequence() when their operand is loop-invariant.
assert((TE.isGather() || TE.State == TreeEntry::SplitVectorize) &&
"Expected gather/split tree entry.");
- uint64_t BaseScale = getScaleToLoopIterations(TE);
+ uint64_t BaseScale = getScaleToLoopIterations(TE, nullptr, U);
if (!PerLaneGatherScale || LoopAwareTripCount == 0 || BaseScale <= 1)
return BaseScale;
@@ -16487,7 +16490,8 @@ uint64_t BoUpSLP::getGatherNodeEffectiveScale(const TreeEntry &TE) {
if (isConstant(V))
continue;
++N;
- uint64_t LaneScale = std::min(getScaleToLoopIterations(TE, V), BaseScale);
+ uint64_t LaneScale =
+ std::min(getScaleToLoopIterations(TE, V, U), BaseScale);
Sum = SaturatingAdd(Sum, LaneScale, &Overflow);
if (Overflow)
return BaseScale;
@@ -18839,8 +18843,9 @@ static T *performExtractsShuffleAction(
return Prev;
}
-InstructionCost BoUpSLP::calculateTreeCostAndTrimNonProfitable(
- ArrayRef<Value *> VectorizedVals) {
+InstructionCost
+BoUpSLP::calculateTreeCostAndTrimNonProfitable(ArrayRef<Value *> VectorizedVals,
+ Instruction *RdxRoot) {
// FIXME: support buildvector of the gather nodes with struct types.
if (any_of(VectorizableTree, [&](const std::unique_ptr<TreeEntry> &TE) {
return TE->isGather() &&
@@ -18960,8 +18965,10 @@ InstructionCost BoUpSLP::calculateTreeCostAndTrimNonProfitable(
}
}
if (!CostIsFree && !Scale) {
- Scale = IsGatherLike ? getGatherNodeEffectiveScale(TE)
- : getScaleToLoopIterations(TE);
+ Scale =
+ IsGatherLike
+ ? getGatherNodeEffectiveScale(TE, TE.Idx == 0 ? RdxRoot : nullptr)
+ : getScaleToLoopIterations(TE);
C *= Scale;
EntryToScale.try_emplace(&TE, Scale);
if (!TE.isGather() && TE.hasState()) {
@@ -29837,7 +29844,8 @@ public:
V.transformNodes();
V.computeMinimumValueSizes();
- InstructionCost TreeCost = V.calculateTreeCostAndTrimNonProfitable(VL);
+ InstructionCost TreeCost =
+ V.calculateTreeCostAndTrimNonProfitable(VL, RdxRootInst);
V.buildExternalUses(LocalExternallyUsedValues);
InstructionCost ReductionCost =
Performance
The image below captures the post-patch performance improvement. Although, if we compare this to the original baseline I displayed at the beginning of this writeup, we can see an increase in issued instructions, and a slight decrease in vector instructions.

However, the total cycles stays about the same to the baseline! 🥹